Core concepts
The semantic layer
AgentData sits between your raw databases and whoever (or whatever) asks questions. Instead of exposing tables and columns, it exposes a business model: entities, measures and dimensions with human-readable names. Questions are answered against that model, so the same query works regardless of how the underlying tables are shaped or which engine runs it.
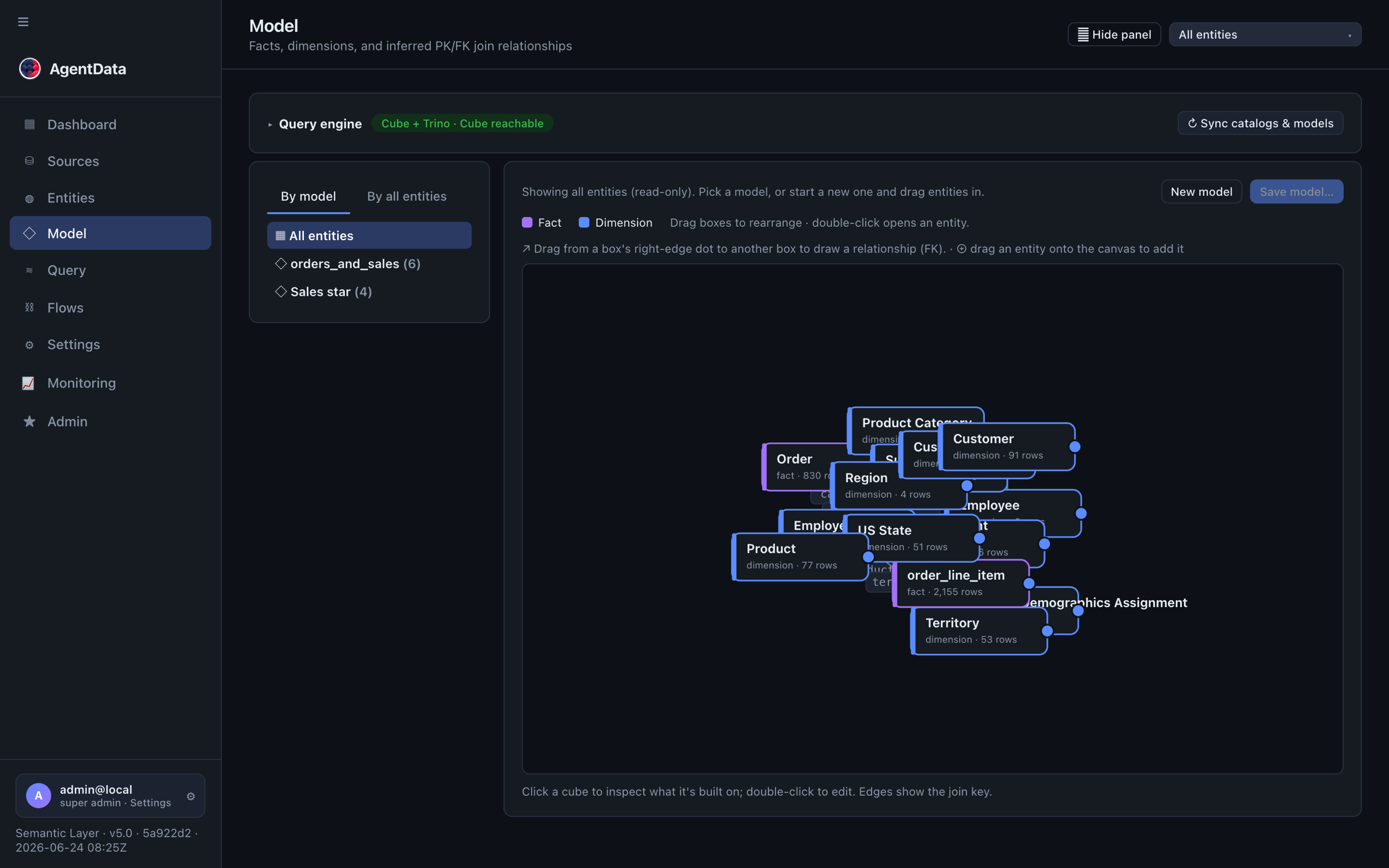
Entities
An entity is a business object discovered from your schema. Each has a role:
- Fact — something measurable (orders, transactions). Usually large tables.
- Dimension — something descriptive (customer, product). Usually small tables.
An entity can have multiple bindings to physical tables across sources. When the same entity (say, Customer) exists in several systems, AgentData collapses them into one entity with merged bindings.
Entities move through a lifecycle: pending_review → confirmed (queryable), with optional rejected or archived. You confirm the model once; queries only ever hit confirmed entities.
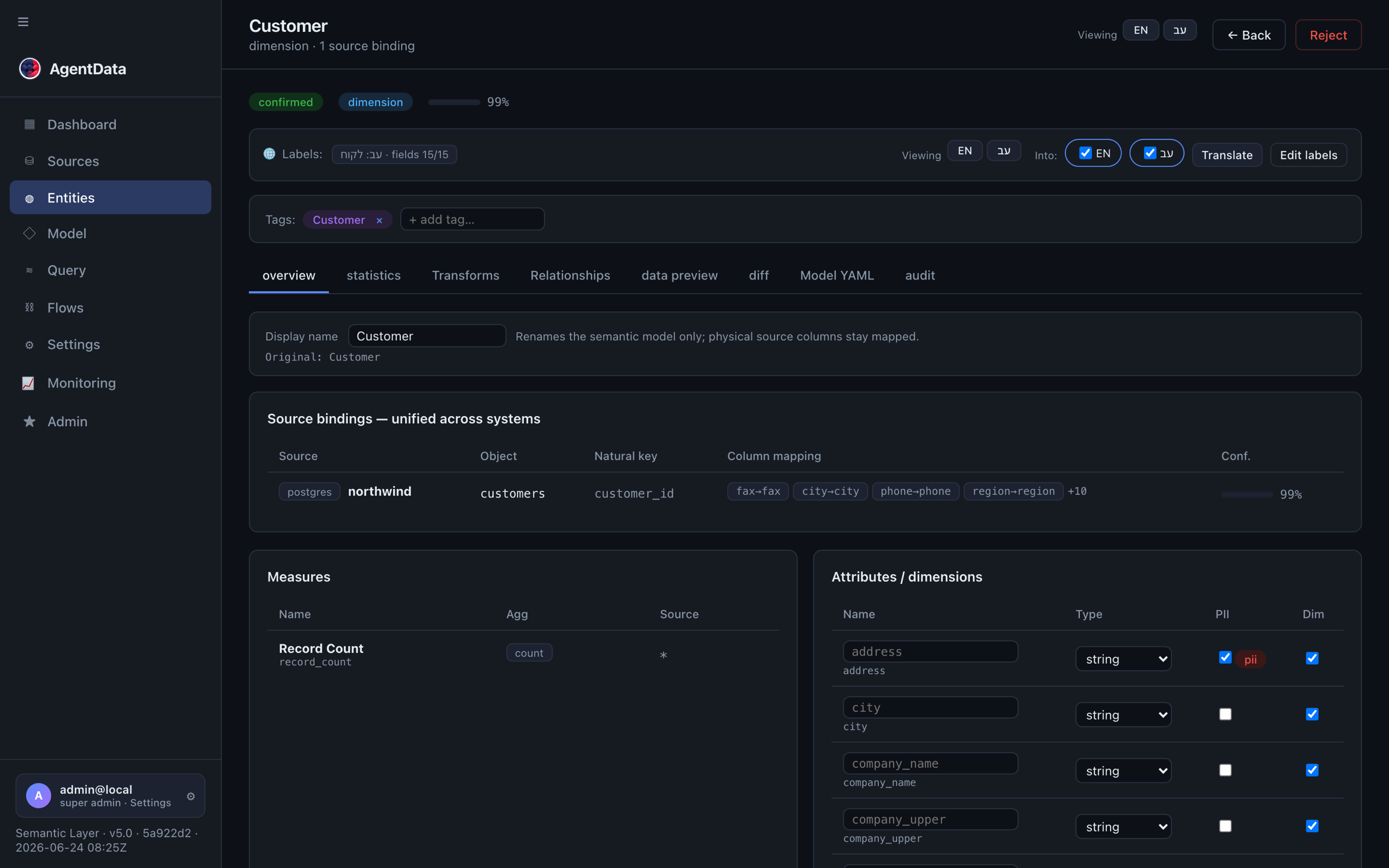
Attributes and measures
- Attributes are dimensions and descriptors — canonical name, physical name, type, and a PII flag.
- Measures are aggregatable metrics:
sum,avg,count, or a custom SQL expression such asunit_price * qty * (1 - discount).
A column map ties each canonical attribute to a physical column or SQL expression. Because it's engine-agnostic, the same mapping works whether queries run through the built-in shim or through Cube + Trino.
Each entity has a detail view showing its source bindings, column mapping, measures and attributes (with PII flags):
The Model view shows the whole semantic model — facts, dimensions and the inferred PK/FK join relationships between them:
Query execution
Question ──▶ Planner (LLM) ──▶ Structured query ──▶ Validator ──▶ Executor ──▶ Result
- Planner — the LLM turns your question into a structured query against the model (never raw SQL from the LLM).
- Validator — checks the query is valid against confirmed entities and measures.
- Executor — runs it:
- Shim (default) — pushes down per-source and merges in Python. Exact for
sum/count; approximate foravg/distinct countacross sources. - Cube + Trino (federation) — exact cross-source joins and measures via a federated engine.
- Shim (default) — pushes down per-source and merges in Python. Exact for
Privacy model
What the LLM sees and doesn't see:
| Reaches the LLM | Never reaches the LLM |
|---|---|
| Entity / attribute / measure names | Row data |
| Your question | Query results |
| Embeddings |
The generated query runs locally against your sources; only the result is returned to you. Small samples captured during profiling are used purely for discovery and classification — not sent to the LLM.
Self-hosting & air-gapped
AgentData can run with no external egress at all. Point it at a local OpenAI-compatible model server and nothing leaves your network:
ai:
provider: openai
base_url: "http://localhost:11434/v1" # Ollama / vLLM / TGI
Other options:
- AWS Bedrock with VPC PrivateLink — LLM traffic stays on AWS's private network; auth via instance IAM role; Bedrock doesn't retain prompts.
- Anthropic cloud — simplest; external egress to
api.anthropic.com. Best for non-sensitive or evaluation use.
Source credentials are encrypted at rest, and adapters enforce read-only access. An optional per-tenant policy (allow_llm_egress, allow_prospecting) lets you lock egress down further. For the full deployment posture — fail-closed MCP auth, the data-egress policy, audit logging and the recommended setup for regulated clients — see MCP & data-egress security.